




At Point, we are evaluating the use of automated, AI-generated routing and responses to customer emails. By doing so, we can provide faster, more consistent support while freeing our team to focus on higher-value, personalized interactions with homeowners. Automating customer interactions, however, requires an exceptionally high degree of confidence.
To ensure we deliver the same level of quality and care as a human agent, we’ve developed an internal evaluation framework that measures the quality of AI-generated responses. This framework allows us to automatically judge not just whether the AI used the “right words,” but whether it conveyed the correct meaning and included the information our homeowners depend on.
By grounding our evaluation in the outcomes that matter most—clarity, completeness, and accuracy—we can safely scale automation while maintaining the exceptional customer experience Point is known for.
Measurement against golden dataset
When evaluating the quality of a generated email draft, we assume the existence of an ideal—or "golden"—response that the draft should closely resemble. Rather than striving for a “word for word” match, our goal is to measure whether the generated response captures the intended meaning. While tone matters, our focus is on measuring how well the generated draft conveys the same meaning as the golden email.
Ultimately, this task comes down to comparing the similarity between texts—an area that has been extensively studied[4]. A widely adopted approach in the field of LLMs is to calculate vector similarities between embeddings, which enables comparison based on meaning rather than exact wording[5].
For this project, however, we needed an approach that aligns closely with human judgment and is explainable—for example, this email should include certain key points and avoid others.
Instead of relying on a single success metric, we aimed for a more fine-grained assessment of quality, focusing on three key dimensions:
- Recall – Does the generated response include all the essential information it’s supposed to?
- Precision – Does it avoid introducing unnecessary or irrelevant details?
- Accuracy – Does it convey correct and factual information?
Evaluation framework
The first step was to define the appropriate unit of measurement. We considered several options:
- Atomic facts – Highly granular, allowing detailed tracking of individual facts for precision and recall[3].
- Statements or subjects – Aligns more closely with how human reviewers assess content (e.g., “Did it mention the return window?”)[6].
- Whole answer – Quicker to evaluate, but too coarse to distinguish between missing information, factual errors, or verbosity[7].
We chose to measure responses at the statement level, as this provides a practical balance between granularity and interpretability. While atomic facts offer a more fine-grained approach, they proved too detailed for our purposes. Instead, we use units like “Identity document: received and accepted on June 29, 2025,” which bundle multiple atomic facts into a single, coherent statement. This abstraction allows us to meaningfully compute precision, recall, and accuracy for each draft.
One of the main reasons we favor statements over atomic facts is that they allow us to evaluate the metrics based on meaningful subjects rather than incidental details. For instance, if the expected statement is “mortgage received” and the generated draft says “mortgage received on July 15, 2025,” we don’t want to penalize precision just because an additional—but accurate—detail was included. Evaluating at the statement level ensures we capture the essential information without punishing valid elaboration.
That said, we recognize the trade-off: this approach shifts the responsibility of determining whether a full statement is correct onto the comparison mechanism itself, which must make a holistic judgment rather than relying on fact-level granularity.
Extracting statements
With the unit of measurement defined, the next step was to compare the statements in each generated email draft against a manually curated list of reference statements—what we refer to as expected statements. These statements capture only the essential product-related content and intentionally exclude generic or conversational phrases such as “Hope you are doing well,” “I’m here to help,” or “Don’t hesitate to contact us.”
Example of expected statements:
ID document not received
mortgage document not received
education not complete
estimate issued but not accepted
next steps: check dashboard regularly and complete required tasks
The next task was to extract comparable statements from the generated responses. For this, we used the gpt-4.1 model with a carefully crafted prompt that described the specific subjects we care about—such as identity verification, mortgage documents, appraisal status, etc. This guided the model to ignore irrelevant or boilerplate content and focus only on the information that matters. We refer to the output of this step as generated statements.
Comparing statements
To compare generated statements with expected statements, we adopted an annotation approach inspired by[2]. The process involved labeling each statement based on its correspondence and correctness:
- For each generated statement, we assigned one of the following labels:
- R – Relevant and correct: Matches an expected statement.
- X – Incorrect: Contradicts or misrepresents an expected statement.
- E – Extra: Not present in the expected list and not required.
- For each expected statement, we labeled:
- A – Addressed: Covered by a matching generated statement.
- NA – Not Addressed: Missing from the generated output.
We used the gpt-4.1 model to perform this annotation, guided by a detailed prompt. The prompt included domain-specific synonym mappings—for example, treating estimate, offer, and investment as equivalent terms—to ensure accurate semantic comparisons between statements.
Calculating precision, recall, and accuracy
To calculate the evaluation metrics, we used standard formulas commonly applied in information retrieval[1]:
- Precision measures the proportion of generated statements that are relevant—i.e., those that match the expected content
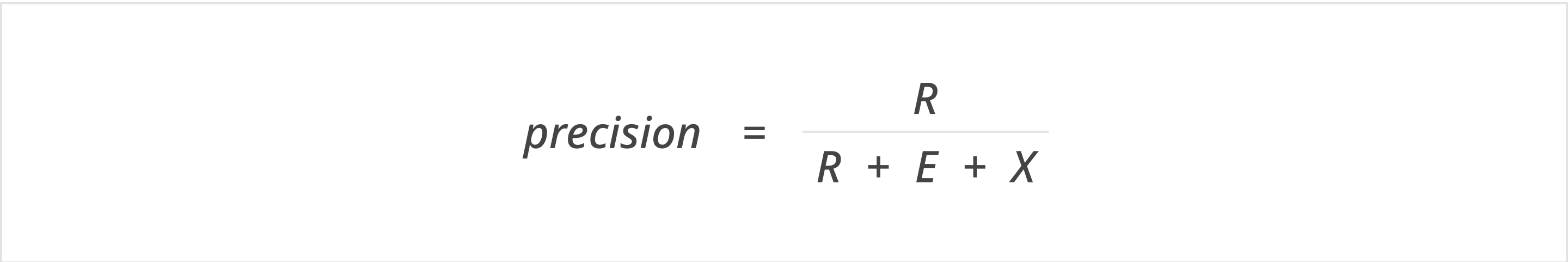
- Recall captures the fraction of expected statements that were successfully addressed in the generated draft
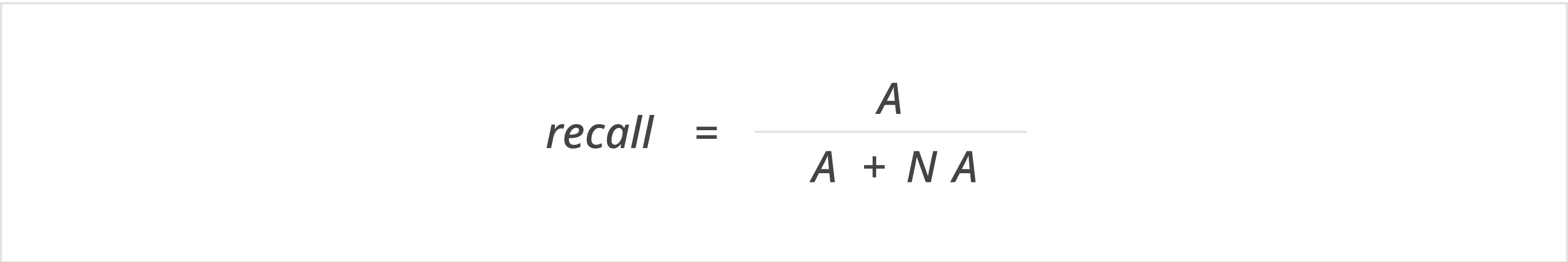
- Accuracy reflects the proportion of correct statements among those that could be judged as either correct or incorrect
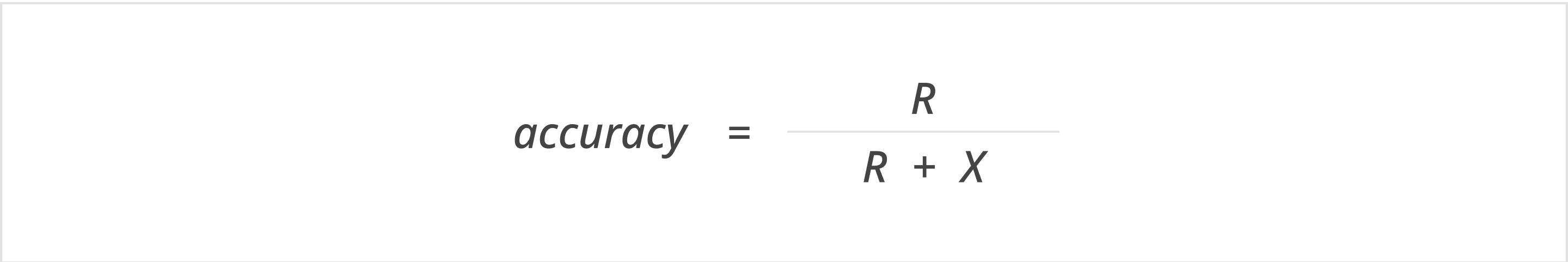
The accuracy formula aligns with the traditional definition of correctness as correct / total. However, since we cannot determine the correctness of extra (unexpected) statements, we exclude them from the accuracy calculation.
Example
This section walks through a concrete example of how we evaluate a generated email draft against a set of expected statements. Suppose our agent produces the following email:
Thank you for checking in! At this time, we are still waiting to receive your Identity document and your Mortgage document, both requested on July 3rd, 2025. Once we have these documents, we can continue moving forward with your Home Equity Investment process. I also want to let you know that you have successfully completed the product education requirement by passing the product quiz on July 4th, 2025, so no further action is needed there. Next steps: please submit the requested documents at your earliest convenience. Meanwhile, check your dashboard regularly and complete any required tasks to keep your application progressing smoothly. If you have any other questions or need assistance, feel free to reach out. We're here to help!
The corresponding expected statements for this test case are:
- ID document received
- mortgage document received
- education complete via quiz
- estimate issued but not accepted
- next steps: check dashboard regularly and complete required tasks
Step 1: Extract generated statements
From the draft email, we extract the product-relevant statements:
identity document: not received
mortgage statement: not received
product education: requirement completed
dashboard: check regularly and complete required tasks
identity document: next step is to submit the requested document
mortgage statement: next step is to submit the requested documentStep 2: Annotate generated statements
Each generated statement is annotated as follows:
- R – Relevant and correct
- X – Incorrect (contradicts expected)
- E – Extra (not in expected set)
Annotations:
X – identity document: not received
X – mortgage statement: not received
R – product education: requirement completed
R – dashboard: check regularly and complete required tasks
E – identity document: next step is to submit the requested document
E – mortgage statement: next step is to submit the requested documentSummary: R = 2, X = 2, E = 2
Step 3: Annotate expected statements
Each expected statement is annotated as:
A – Addressed by the draft
- NA – Not addressed
Annotations:
NA – ID document received
NA – mortgage document received
A – education complete via quiz
NA – estimate issued but not accepted
A – next steps: check dashboard regularly and complete required tasksSummary: A = 2, NA = 3
Step 4: Calculate metrics
Using the annotations, we compute the metrics:

These values give us a clear, fine-grained view of how well the generated email aligns with expectations in terms of relevance, completeness, and correctness.

Conclusion
This approach enables the calculation of precision, recall, and accuracy for automatically generated emails based on a human-defined set of expected statements. Its effectiveness in automated testing hinges on the ability of a large language model (LLM) to reliably extract and compare statements from the generated responses.
Our experiments demonstrated that the gpt-4.1 model performs this task well, provided the prompt includes clear guidance on domain-specific concepts. Given the inherent variability in text generation, it's important to evaluate these metrics across a large dataset and average the results to obtain stable and reliable performance indicators.
Further development
This evaluation approach can be extended to compare generated responses not only against a predefined list of expected statements, but also against a golden email—for instance, a real message previously sent to a customer by a human agent. In this case, the process involves extracting the expected statements directly from the golden email itself.
Another promising direction is using these metrics to support automated prompt tuning with frameworks like DSPy. To enable this, individual metrics must be combined into a single optimization objective. Following the methodology in[1], we recommend using the F-measure, which balances precision and recall:

where P - precision, R - recall
While Fβ=1 is appropriate when precision and recall are equally important, in our domain we place more weight on recall—it's more critical that key information is included, even if some additional content appears. As such, we prefer using Fβ=3 or Fβ=5, which emphasizes recall more heavily in the combined metric.
No income? No problem. Get a home equity solution that works for more people.
Prequalify in 60 seconds with no need for perfect credit.
Show me my offer
Frequently asked questions
.png)
Thank you for subscribing!
.webp)
You’re good to go — enjoy your resource.
You’re good to go — enjoy your resource.
Frequently Asked Questions
1. Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval (Chapter 8). Cambridge University Press. https://nlp.stanford.edu/IR-book/pdf/08eval.pdf
2. Voorhees, E. M. (2003). Overview of the TREC 2003 Question Answering Track. National Institute of Standards and Technology (NIST). https://trec.nist.gov/pubs/trec12/papers/QA.OVERVIEW.pdf
3. Min, S., Hwang, Y., Khot, T., Khashabi, D., Hajishirzi, H., & Bosselut, A. (2023). FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long-form Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). https://aclanthology.org/2023.emnlp-main.741.pdf
4. Chandrasekaran, D., & Mago, V. (2021). Evolution of Semantic Similarity — A Survey. ACM Computing Surveys, 54(2), 1–37.
https://doi.org/10.1145/3440755
5. OpenAI. (2025). Vector embeddings. OpenAI Platform Documentation. Retrieved August 25, 2025.
https://platform.openai.com/docs/guides/embeddings/similarity-embeddings?utm_source=chatgpt.com
6. Bar-Haim, R., Eden, L., Friedman, R., Kantor, Y., Lahav, D., & Slonim, N. (2020). From Arguments to Key Points: Towards Automatic Argument Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020) (pp. 4029–4039). Association for Computational Linguistics.
https://doi.org/10.18653/v1/2020.acl-main.371
7. Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., & Stoica, I. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. In Advances in Neural Information Processing Systems 36 (NeurIPS 2023), Datasets and Benchmarks Trackhttps://proceedings.neurips.cc/paper_files/paper/2023/hash/91f18a1287b398d378ef22505bf41832-Abstract-Datasets_and_Benchmarks.html








